Inhalt
- Was ist Duplicate Content?
- Auswirkungen von Duplicate Content
- Praxistipp für B2B-Hersteller mit Produktkbeschreibungen
- Wie findet und prüft man Duplicate Content
- Wie bereinigt und vermeindet man Duplicate Content?
- Fazit
dotflow®
dotflow ist die B2B Digitalagentur für smartes Online-Marketing und überzeugende Websites.

Was ist Duplicate Content?
Duplicate Content (engl. „doppelter Inhalt“) bezeichnet die exakte Kopie oder einen nahezu identischen Inhalt auf mehreren URLs. Prinzipiell unterscheidet man zwischen internem Duplicate Content, der innerhalb einer Website auftritt, und externem Duplicate Content, der zwischen verschiedenen Domains besteht. In der Suchmaschinenoptimierung (SEO) spielt dieser Aspekt enorm wichtig und wird als einer der Kernpunkte im Bereich der Onpage-Optimierung betrachtet.
Denn die Vernachlässigung von Duplicate Content kann zu erheblichen Rankingverlusten führen, was wiederum einen starken Rückgang des Traffic auf der betroffenen Website zur Folge hat. Darüber hinaus besteht die Gefahr, dass Google Webseiten mit starkem Duplicate Content abstraft und aus dem Index entfernt. Besonders problematisch wird es, wenn der duplizierte Inhalt geistiges Eigentum darstellt und unerlaubt verwendet wird. Dies kann nicht nur zu rechtlichen Konsequenzen führen, sondern auch das Ansehen der betroffenen Website nachhaltig schädigen.
Summary
- Inhaltlich gleicher Content auf der eigenen aber auch verschiedenen Seiten heißen Duplicate Content
- Wird dieser nicht schnell gefunden oder bereinigt, sind Schäden für den Umsatz durch ausbleibende oder rückgehende Suchmaschinenplatzierungen absehbar
- Es gibt verschiedene Arten von Duplikaten, die aber jeweils abgemildert, bereinigt oder vermieden werden können
- Insbesondere für B2B Produktbeschreibungen ist das Thema extrem wichtig, da Texte zwangsläufig an vielen Stellen auftauchen werden
Den Shortcut gehen Sie, in dem Sie webbasierte Tools nutzen um Duplicate Content zu erkennen. Zur Prüfen und Bereinigen springen Sie in die entsprechenden Ratgeber Absätze dazu. Dieser Artikel dient dem Verständnis des Konzepts im Kontext der Suchmaschinenoptimierung.
Auswirkungen von Duplicate Content
Die Auswirkungen von Duplicate Content auf Ihrer Website sind vielfältig und können die die Online-Marketing Performance Ihrer Webpräsenz nachhaltig beeinträchtigen. Lassen Sie uns kurz die möglichen Schäden durch nichterkannten oder nicht behobenen Duplicate Content auf Ihrer Website anschauen:
Rückgang der Rankings:
Neu erstellte Seiten könnten aufgrund von Duplicate Content Schwierigkeiten haben, grundlegend oder erstmalig in die Suchmaschinen Rankings aufgenommen zu werden, während bereits bestehenden Internetseiten drastisch an bestehenden Rankings verlieren können, da die Suchmaschinen inhaltliche Duplikate als Spam deuten und die Autorität Ihrer gesamten Website abstufen.
Traffic- und Umsatzeinbußen:
Weniger Besucher erreichen Ihre Seite das Sie in weniger Suchergebnissen auf für Sie spannende Keywords erscheinen Das wird sich direkt auf die Conversionrates und den Umsatz auswirken, da die Suchenden auf die Websites Ihrer Konkurrenz gehen.
Abstrafungen durch Suchmaschinen:
Suchmaschinen könnten Maßnahmen ergreifen, die Ihre Seite weiter in den Rankings herabsetzen, zum Beispiel auch die Bewertung der Domain Authority negativ beeinflussen.
Reputationsschäden:
Offensichtlicher Duplicate-Content kann das Vertrauen der Nutzer und das Ansehen bei Partnern beeinträchtigen.
Rechtliche Risiken:
Die unerlaubte Nutzung urheberrechtlich geschützter Inhalte kann zu rechtlichen Konsequenzen führen.
Die Folgen von nicht behobenem Duplicate Content für Ihre Website sind wie Sie sehen zahlreich und Umsatzkritisch. Sie können die Online-Performance erheblich einschränken oder limitieren.
Um Schaden zu vermeiden oder zu minimieren, ist es wichtig, proaktiv zu sein, Duplikate ausfindig zu machen, zu vermeiden oder zu beheben.
Im weiteren Verlauf dieses Beitrags werden wir uns darauf konzentrieren, wie Sie Duplicate Content effektiv identifizieren, vermeiden und bereinigen können.
Arten von Duplicate Content
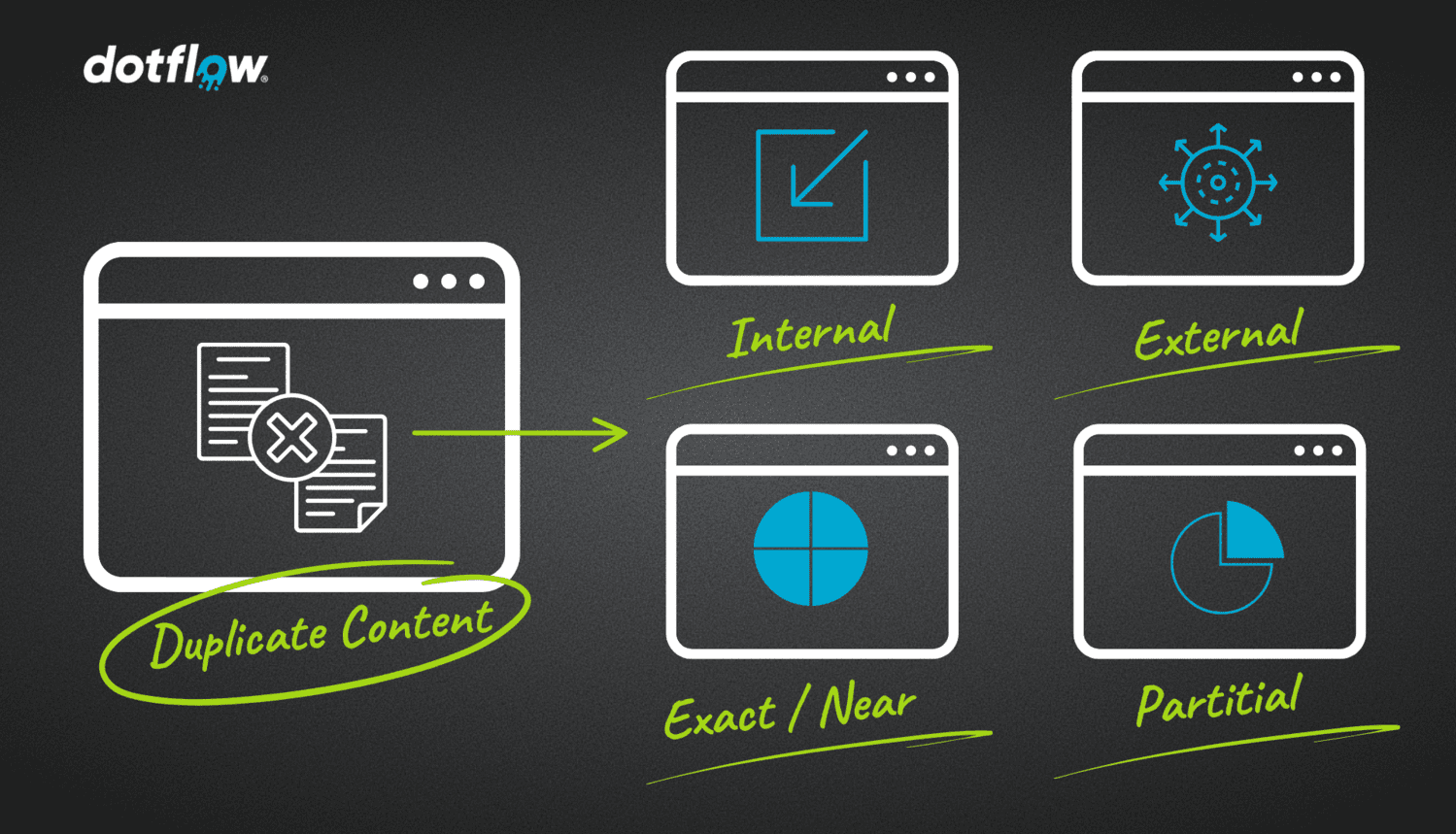
Duplicate Content ist nicht gleich Duplicate Content. Er kann in verschiedene Typen und Kategorien eingeteilt werden. So kann zum Beispiel das Duplikat auf derselben Website sprich intern liegen, oder auf einer externen Ressource, also externer Duplicate Content sein. Außerdem kann es verschiedene Klassifikationen an Duplikaten geben – vom Vollplagiat bis zu teilweiser Dopplung. Die Unterschiede zeigen sich in den Auswirkungen auf das SEO Ergebnis. Die Unterschiede zu kennen, hilft aber genau so dabei, den Content der betroffen ist zu finden, oder beim erstellen schon zu vermeiden in die doppelte Nutzung zu geraten.
Die ersten Drei Punkte: Exact Duplicate-Content, Partial Duplicate-Content und Near Duplicate Content sind Kategorien die wir uns genauer anschauen. Punkt und 5 (Intern und Extern) sind die verschiedenen Arten.
-
Exact Duplicate Content (100% Duplikat)
Es werden ein oder mehrere Indikatoren gefunden, die indirekt oder direkt auf ein Duplikat hinweisen. Meist handelt es sich hierbei um Content der 1 zu 1 Kopiert wurde. Aber auch Design spezifische Elemente, wie beispielsweise Bilder werden abgestraft, da es nicht als unique Content gewertet wird, sofern es sich um eine Kopie handelt. In diesem Bereich egal ob Content oder Grafik besteht auch die Gefahr einer rechtlichen Abstrafung durch den Diebstahl geistigen Eigentums. Um gravierende rechtliche als auch SEO-bedingte Auswirkungen zu vermeiden sollten Sie folgende Fehler sofort beseitigen oder vermeiden.
Doppelter Inhalt ohne Canonical-Tag auf der eigenen Seite
Copy Paste fremder oder eigener Texte
Exakte Übernahme von visuellen Elementen wie Bildern oder Grafiken -
Partitial Duplicate-Content (Teilweise Duplikat)
Ein wesentlicher Teil des selben Contents befindet sich auf einer eigenen oder externen URL. Je nach Ausmaß kann hier ein relevanter oder unwichtiger Verstoß vorliegen. Wurden fremde Textabschnitte kopiert, dann ist gilt es diesen zu entfernen. Haben Sie eine zusätzliche Landingpage erschaffen, welche sich die selben Teilelemente wie bspw. Referenzen teilen, dann kann der Google-Algorithmus gut unterscheiden, dass es sich hier um kein „Duplikate“ per se handelt. In jedem Fall sollten Sie den Duplicate Content prüfen.
Fehlerhaftes Umschreiben (z.B. Definition klingen stark ähnlich)
Verwendung von Teilkomponenten aus Landingpages (Referenzen, Erfahrungen)
Kopieren von kleineren Textabschnitten – das könnten auch Störer sein -
Near Duplicate Content
Der Content stützt sich auf die Informationen von anderen Quellen, und wird ohne eigene Gedanken umgeschrieben. Hier macht es einen guten Eindruck die Quellen zu erwähnen. Im engernen Sinne entsteht aber kein Duplicate Content.
Hinweis: Sie sollten immer eigenen einzigartigen Content erstellen und fremde Informationen um eigene Gedanken anreichern, um Wertvoll für die Suchmaschine und den User zu wirken. Bei Legal-Definitionen ist das sicher schwer und manchmal erscheint es unnötig. Versuchen Sie aber IMMER eigene Sichten einzubringen, eigenen Mehrwert zu schaffen. -
Interner Duplicate Content
Interner Duplicate Content – also Duplikate auf derselben Website – tritt auf, wenn dieselben oder sehr ähnliche Inhalte mehrfach innerhalb einer Domain vorkommen, oft aufgrund von URL-Variationen, Session-IDs oder ähnlichen Seitenstrukturen. Diese Duplikation kann die Suchmaschinenoptimierung negativ beeinflussen, da sie die Klarheit der Indexierung verwässert. Beispiele dazu können sein:
URL-Variationen: Verschiedene URLs führen zur gleichen Seite, z.B.domain.tld/produktunddomain.tld/produkt/?farbe=rot.
Session-IDs in URLs: Jede Sitzung erzeugt eine einzigartige URL für die gleiche Seite, wiedomain.tld/produkt?sessionid=123.
Druckfreundliche Versionen von Seiten: Zusätzliche URLs für druckbare Inhalte, z.B.domain.tld/produkt/druckversion.
Produktseiten, die über mehrere Kategorien erreichbar sind: Identische Produktseiten unter verschiedenen Kategorie-URLs, wiedomain.tld/kategorie1/produktunddomain.tld/kategorie2/produkt.
HTTP- und HTTPS-Versionen der Website:
Das parallele Betreiben vonhttp://domain.tldundhttps://domain.tldwird Duplicate Content erzeugen. Eine permanenter redirect per 301 Weiterleitung vermeidet das schon und sichert den Datenschutz.
WWW- und Nicht-WWW Versionen der Website:
Suchmaschinen sehenwww.domain.tldunddomain.tldals zwei unterschiedliche Seiten an. Das verursacht Duplicate Content. Die 301 Weiterleitung behebt das aber schon.
Fehlende Trailing Slashes:
Die URLsdomain.tld/pfadunddomain.tld/pfad/werden auch als zwei verschiedene Content Pieces betrachtet… Kleinlich aber Fakt. Auch hier hilft die 301 Weiterleitung aber auch das Sperren der Indexierung durch die robots.txt Datei.
(Ein Trailing Slash ist der abschließende Schrägstrich (/) am Ende einer URL. Er zeigt an, dass es sich um ein Verzeichnis und nicht um eine Datei handelt)
Deckungsgleiche Inhalte in verschiedenen Sprachversionen:
Inhalte aufdomain.tld/deunddomain.tld/enwerden ohne hreflang-Tags zur Angabe der Sprachversionen als Duplikate gewertet.
-
Externer Duplicate Content
Externer Duplicate Content liegt vor, wenn identische oder zumindest sehr ähnliche Inhalte auf verschiedenen Domains gefunden werden. Dies kann oft durch die Wiederverwendung von Inhalten über mehrere Websites hinweg geschehen, sei es durch Syndizierung, Content-Partnerschaften oder unerlaubtes Kopieren.
*Was ist Syndizierung?
Syndizierung in unserem Kontext ist das Verfahren, Inhalte wie Artikel oder Blogposts im Sinne der Reichweite auf anderen Websites zur Verfügung zu stellen. Normalerweise sollte hier auf die Ursprüngliche Quelle verwiesen werden oder ein Canonical Tag genutzt werden.
Syndizierte Inhalte:
Artikel, die original aufdomainA.tld/blogpostveröffentlicht und dann aufdomainB.tld/blogpost-syndicatedgeteilt wurden.
Zuliefererbeschreibungen (Sie sind z.B. OEM, Hersteller etc.):
Produktbeschreibungen, die von einem Hersteller bereitgestellt und auf verschiedenen Händlerseiten wieretailerA.tld/productundretailerB.tld/productverwendet werden.
Geklonte Websites:
Vollständig duplizierte Websites unter verschiedenen Domains, z.B.originaldomain.tldundclonedomain.tld.
Praxistipp für B2B-Hersteller mit Produktkbeschreibungen
Ihre Produktstammdaten sind Goldwert und mit hohem Aufwand verbunden. Sie können Ihr SEO Fundament darstellen und für wahnsinnigen Traffic sorgen. Wenn Sie aber auch indirekt Vertrieb machen und Händler für Sie Produkte anbieten ODER sie schlicht und einfach mehrere Verkaufskanäle haben, denken Sie darüber nach, zumindest die auf die Kunden ausgerichteten Texte auf Ihrer Seite leicht differenziert vorzuhalten. Gleichzeitig sollte aber die Marke und die Produktnamen den Suchmaschinen in Ihrer Entität „Organization“ bekannt gemacht sein – das erreichen Sie z.B. über Structured Data. So kann z.B. google Schlüsse ziehen, dass Sie der originale Verfasser dieser Texte sind. Ebenso sollten Sie permanent das Netz prüfen auf Duplikate.
Wie findet und prüft man Duplicate Content
Um den Status der eigenen Website einmalig aber auch dauerhaft hinsichtlich von Duplikaten zu erkennen, können für die Prüfung und zum Auffinden potenzieller Duplikate verschiedene Herangehensweisen und Tools genutzt werden. Das Auffinden ist natürlich der erste Weg der Besserung. Wie dieser bei Bedarf entfernt oder idealerweise vermieden werden kann, schauen wir uns später an. Wir als SEO Agentur gehen wie folgt an das Thema Prüfung für uns und unsere B2B Kunden ran:
Prüfung via google search console (ehemals google Webmaster Tools)
Um Duplicate Content in der Google Search Console zu finden, gehen Sie in Ihrem Account in den Bereich „Abdeckung“. Hier finden Sie Infos zum Indexierungsstatus Ihrer Domain und URLs und auch zu Problemen. Meldungen wie „Duplikat, Nutzerkanonische Seite nicht festgelegt“ oder „Duplikat, Google hat eine andere kanonische Seite ausgewählt“ deutet auf doppelte Hinweise hin und sollten dann auf der jeweiligen Unterseite manuell geprüft werden.
Das „URL-Prüftool“ zeigt Ihnen klar, wie Google einzelne URLs einschätzt und ob sie als Duplikat gelten. Diese Prüfung sollten Sie regelmäßig durchführen.
Screaming Frog (Mit bestes Tool für On-Page SEO)
Screaming Frog ist das Schweizer Taschenmesser der Suchmaschinenoptimierung. Das Tool läuft auf Ihrem Computer und ist in seinen Möglichkeiten fast unerreicht breit aufgestellt, für Online-Marketer aber oft zu komplex. Dennoch ist es ein probates Tool zur Erkennung von Duplikaten. Um dieses Ziel zu erreichen, laden Sie sich ganz einfach den Screaming Frog kostenlos herunter, installieren und öffnen es und Crawlen Ihre eigene Websiteadresse und konfigurieren das Tool im Tab: Inhalt: auf Duplikate und sagen dem Tool was „Near Duplicate Content“ in % für Sie bedeutet. Danach finden Sie Angaben zu Problemen in Ihrem Content im Reiter „Inhalt“.
Sollten Sie das Tool Screaming Frog verwenden wollen, empfehlen wir Ihnen die folgende Anleitung auf Youtube.
Siteliner
Siteliner ist ein Webbasiertes Tool das Ihnen sehr schnell und einfach Hinweise auf Duplikate auf Ihrer Website gibt. Nach Eingabe Ihrer Domain warten Sie kurz und sehen dann mehrere Metriken. EIne davon ist Duplicate Content. Siteliner zeigt Ihnen sogar in Abstufungen, wieviel Anteile an Duplikaten Seiten haben. Beispielsweise der Footer oder Störerelemente die auf mehreren Seiten auftauchen.
Copyscape
Auch Copyscape ist ein webbasiertes Tool zur Feststellung von Plagiaten. Ebenso einfach wie Siteliner zu verwenden entdecken Sie Duplicates in Sekundenschnelle und hier auch externen Duplicate Content.
Das Tool ist grundlegend kostenfrei.
sistrix (bestes SEO Tool auf dem deutschen Markt)
Wir sind eine für sistrix zertifizierte SEO Agentur. Daher nutzen wir für unsere tägliche Arbeit auch sistrix.
Das Tool ist zwar nicht kostenlos, bietet aber viel mehr als die Erkennung von Content Duplikaten.
Wenn Sie das für sich testen wollen, besuchen Sie Ihren sistrix Account und dort Ihr angelegtes Projekt für Ihre Website. Dort erhalten Sie nach einem Crawl Ihrer Seite Ergebnisse zum On-Page Status und somit auch zu Duplicate Content auf Ihrer Website.
Wie sie sehen ist es auch ohne Kosten für Tools einfach einen Überblick über Probleme auf Ihrer Website zu bekommen. Wir legen die Prüfung auf Content Duplicates allen B2B Anbietern mit Interesse an Leads via Online-Marketing ans Herz und unterstützen Sie auch gerne um Ihre SEO PS auf die Straße zu bekommen.
Wie bereinigt und vermeindet man Duplicate Content?
Wenn Sie nun potenzielle Probleme auf Ihrer Webpräsenz ausfindig gemacht haben, sollte dieser schnellstmöglich behoben werden. Dazu gibt es, je nachdem welche Art und Kategorie von Duplicates vorliegen verschiedene Möglichkeiten zur Bereinigung. Der beste Weg ist natürlich trotzdem, einfach weniger oder gar keinen Duplicate-Content zu erzeugen. Da sich das aber meist kaum realisieren lässt, sind hier die Wege die Ihnen zur Verfügung stehen.
301-Weiterleitung:
Die 301-Weiterleitung ist die permanente Weiterleitung von Nutzern, SEO Crawlern und Co. auf eine vorgeschriebene andere Seite. Seiten mit Duplicates werden so dauerhaft durch die Umleitung umgangen. Die Suchmaschinen, wissen welchen Content sie indexieren sollen und sehen die Duplikate nicht – sie verstehen die Wertigkeit. Die 301 Weiterleitungen können auf CMS wie WordPress in Plugins, ansonsten aber auch über die htaccess Datei eingerichtet werden.
Canonical Tag:
Den Canonical Tag können Sie ebenfalls z.B. bei WordPress und anderen CMS via Plugin setzen. Der Canonical Tag weist google und Co. auf den originalen Content hin und kennzeichnet so das Duplikat aktiv als solches.
Noindex-Tag:
Der Noindex Tag gibt Suchmaschinen wie Bing und google einen klare Information, dass die entsprechend gekennzeichnete Seite nicht in den Index aufgenommen werden soll und somit nicht nur keine Rankings erfährt, sondern auch das die hier hinterlegten Inhalte entweder nur temporär oder unwichtig sind. Sie stellen diesen Tag im Bestfall via eines SEO-Plugins wie Yoast oder Rank Math ein. Ansonsten lösen Sie das via <meta tag> oder http header response.
Robots.txt:
Die robots.txt Datei hilft Ihnen, die Suchmaschinen Crawler, die im Namen der Suchmaschinen Ihre Seite auslesen besser zu steuern. Ob es das Ausschließen spezifischer User-Agent Varianten ist oder der Ausschluss verschiedener Website Bereiche. Mithilfe der Robots.txt Datei haben Sie ein mächtiges Tool zur Seite!
hreflang-Tags:
Der hreflang-Tag hilft Ihnen zur Deklaration für mehrsprachige oder regionale Inhalte.Verwende hreflang-Tags für mehrsprachige oder regionale Inhalte. Sie legen diesen – falls Sie ohne CMS Plugins arbeiten – via Meta Tag an. Wir empfehlen aber die Nutzung von Content Management Systemen wie WordPress samt der entsprechenden SEO-Plugins.
Fazit
Duplicate Content auf Ihrer Website stellt leider ein relevantes Problem mit teils größeren Folgen für Ihre Suchmaschinen Performance dar.
Ob Sie die Duplikate selbst und auf Ihrer eigenen Domain verursacht haben, durch die Natur der Sache von Produktbeschreibungen akzeptieren müssen oder Ihnen gar Content gestohlen wurde – um das volle Potenzial nachhaltigen Suchmaschinentraffics für Ihre Website erziehlen zu können, ist es wichtig, dass Sie in regelmäßigen und eher kurzen Abständen prüfen, ob Sie Probleme mit Duplicate Content haben und diesen dann schnellstmöglich bereinigen und google mitteilen, dass das Problem behoben wurde.
In der Zusammenarbeit mit Textern, SEO-Agenturen und Co. sollte in einem mindestens monatlichen SEO Audit überprüft werden ob alles passt und bei der Erstellung von neuem Content aktiv auf Plagiate geachtet werden.